Irodori-TTSをベースに、長めの文章を扱いやすくするための改変版を用意しました。
主な追加内容:
- 1分以上の長文生成
- WAV/MP3出力
- MP3タグへの生成設定埋め込み
- Windows向け補助バッチ
- モデルのローカル保存とオフライン優先起動
通常の短文生成に加えて、文章を句読点や改行で分割し、チャンクごとに音声生成してから結合することで、比較的長いナレーションや読み上げ音声を作りやすくしています。
目次
ダウンロード
- フルZip版:
ダウンロード
※変更履歴:
2026-06-23 2 …… mp3のコメントに生成情報を埋め込めるようアップデート
2026-06-23 …… 初版
できること
この改変版では、主に以下の機能を追加しています。
- 1分以上の長文生成に対応
- 文章を自動分割して順番に音声生成
- チャンク間に任意の無音時間を挿入
- 最終音声をWAVまたはMP3で出力 (FFmpegが必要)
- MP3出力時に生成設定や入力情報をタグとして埋め込み (2026-06-23 Update)
- JSON / JSONL形式で生成メタデータを保存
- Windows向けの起動バッチを追加
- FFmpegを自動取得
- モデルとCodecを
_modelsフォルダ以下へ保存 - 既定でオフライン優先起動
- モデルが無い場合のみ、オンラインでダウンロードするか確認
3ステップで使う
Windows環境では、基本的に以下の3ステップで使えます。
1. Zipを展開する
フルZip版を任意の場所に展開します。
例:
D:\_Apps.AI\Irodori-TTS-long-mp3
2. WebUIを起動する
windows フォルダ内の以下をダブルクリックします。
_LAUNCH_WebUI_LONG.bat
初回起動時に必要なPython依存関係やFFmpegが不足している場合は、自動でセットアップされます。
モデルとCodecが _models フォルダに無い場合は、オンラインでダウンロードするか確認されます。Y を選ぶと、必要なファイルが _models 以下へ保存されます。
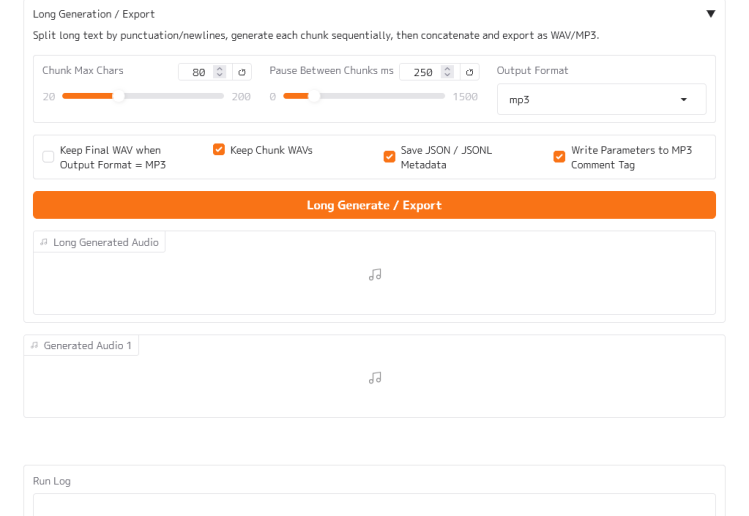
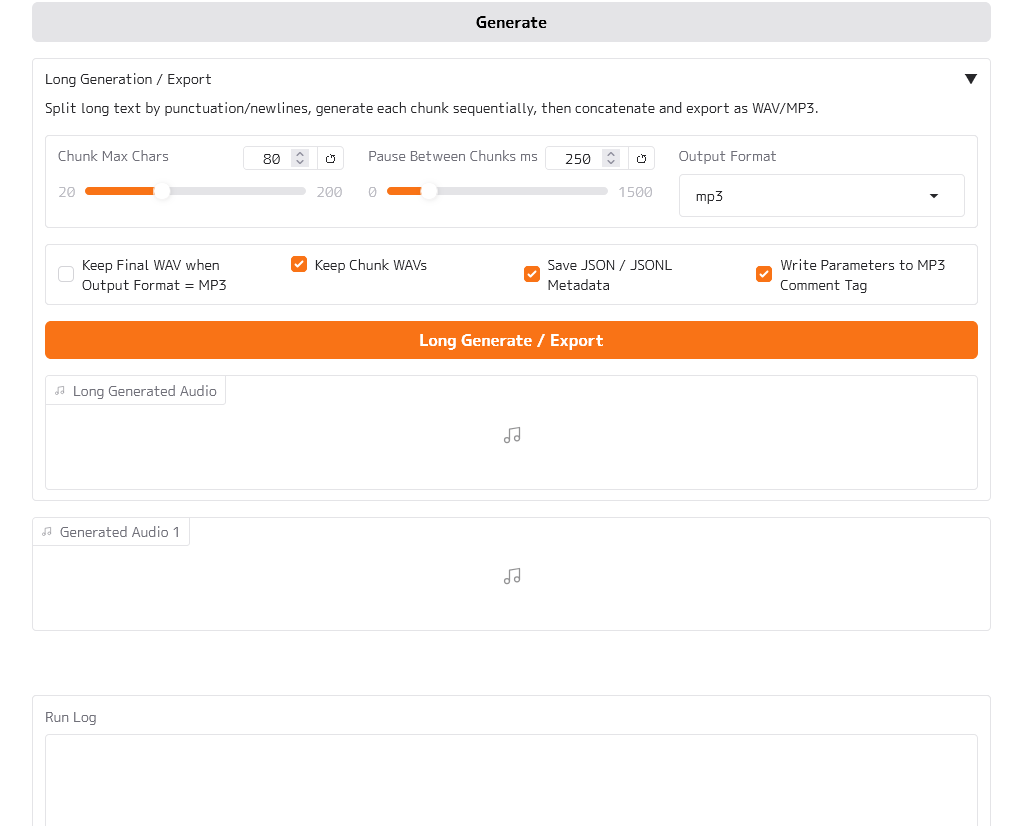
3. Long Generate / Exportを押す
ブラウザでGradio UIが開いたら、Text欄に読み上げたい文章を入力し、必要に応じてCaption / Style Promptを入力します。
長文を出力する場合は、画面内の Long Generation / Export セクションを使い、Long Generate / Export ボタンを押します。
MP3で保存したい場合は、Output Formatを mp3 にしてください。
基本的には Long Generate が上位互換なので、Long Generate のみを使用で問題ありません。
長文生成の仕組み
長文生成では、入力された文章を句読点や改行をもとに分割します。
それぞれのチャンクを順番に音声生成し、最後に1つの音声ファイルとして結合します。
これにより、1回の推論で長すぎる文章を無理に読ませるのではなく、比較的安定した単位に分けて生成できます。
主な設定は以下です。
Chunk Max Chars: 1チャンクあたりの最大文字数Pause Between Chunks ms: チャンク間に入れる無音時間Output Format:wavまたはmp3Keep Chunk WAVs: 分割生成された各チャンクWAVを残すSave JSON / JSONL Metadata: 生成情報をJSON/JSONLで保存Write Parameters to MP3 Comment Tag: MP3タグに生成設定を書き込む
その他
MP3出力について
MP3出力にはFFmpegを使用します。Windows向けバッチでは、FFmpegが見つからない場合に自動でダウンロードし、_vendor フォルダ以下へ配置します。MP3出力を使うことで、Web掲載、動画編集、音声管理などで扱いやすいファイルサイズにできます。
※ 先日公開した ffmpeg-mini でも問題ないと思いますが、今回は念の為フル版を使用しているためDLにはすごく時間がかかりますのでご注意ください。
JSON / JSONLメタデータ
MP3タグとは別に、JSON / JSONL形式でも生成情報を保存できます。こちらは、生成履歴を管理したり、後から同じ条件で再生成したい場合に便利です。
オフライン優先の動作
この配布版では、既定で _models フォルダ以下のローカルモデルを参照します。一度モデルとCodecをダウンロードしておけば、次回以降はローカルファイルを使って起動できます。
モデルが見つからない場合のみ、オンラインに切り替えてダウンロードするか確認されます。完全オフラインで使いたい場合は、事前に以下が揃っている必要があります。
- TTSモデル
- Codec
- tokenizerキャッシュ
- FFmpeg
- Python依存関係
初回セットアップ後は、通常はネットワーク接続なしでも利用しやすい構成になっています。
追加されたWindows用ファイル
windows フォルダには、主に以下の補助ファイルが入っています。
_LAUNCH_WebUI_LONG.bat
_LAUNCH_CLI_LONG.bat
_DOWNLOAD_MODELS.bat
_IRODORI_LOCAL_CONFIG.example.bat
_download_models.py
通常は _LAUNCH_WebUI_LONG.bat を使えばOKです。CLIで長文生成したい場合は、UTF-8のテキストファイルを _LAUNCH_CLI_LONG.bat にドラッグ&ドロップしてください。
モデルだけ先に取得したい場合は、_DOWNLOAD_MODELS.bat を実行します。
ライセンスについて
Irodori-TTS の MIT License を継承しています。(Zip同梱物をご確認ください)
同梱しているコードについては、元プロジェクトのライセンス表記を維持しています。
モデル重みはZipに同梱していません。
初回セットアップ時にユーザー側でダウンロードする形です。モデルの利用条件については、各モデル配布元のライセンスや利用規約を確認してください。
⚠️ 注意: ffmpegのフル版はライセンスが厳しいため、ffmpegのフル版のバイナリを含んだままでは再配布できないと思ってください。別途先日配布した ffmpeg-mini か、再配布の際は ffmpeg を抜いてください。
注意事項
この改変版は非公式版です。
元プロジェクトの開発者による公式配布物ではありません。
また、生成した音声の利用については、使用するモデル、入力内容、音声の用途、公開先の規約などを確認してください。特に、第三者の声に似せた音声、商用利用、公開配布などを行う場合は、権利や規約に注意してください。
まとめ
今回の改変版では、Irodori-TTSをより長文ナレーション向けに使いやすくするため、長文分割生成、MP3出力、タグ埋め込み、Windows向け自動セットアップを追加しました。
短い音声の試作だけでなく、まとまった文章の読み上げ、動画ナレーション、音声素材作成などにも使いやすくなっていると思います。